Total Correlation
The total correlation [Wat60], denoted \(\T{}\), also known as the multi-information or integration, is one generalization of the Mutual Information. It is defined as the amount of information each individual variable carries above and beyond the joint entropy, e.g. the difference between the whole and the sum of its parts:
Two nice features of the total correlation are that it is non-negative and that it is zero if and only if the random variables \(X_{0:n}\) are all independent. Some baseline behavior is good to note also. First its behavior when applied to “giant bit” distributions:
In [1]: from dit import Distribution as D
In [2]: from dit.multivariate import total_correlation as T
In [3]: [ T(D(['0'*n, '1'*n], [0.5, 0.5])) for n in range(2, 6) ]
Out[3]: [1.0, 2.0, 3.0, 4.0]
So we see that for giant bit distributions, the total correlation is equal to one less than the number of variables. The second type of distribution to consider is general parity distributions:
In [4]: from dit.example_dists import n_mod_m
In [5]: [ T(n_mod_m(n, 2)) for n in range(3, 6) ]
Out[5]: [1.0, 1.0, 1.0]
In [6]: [ T(n_mod_m(3, m)) for m in range(2, 5) ]
Out[6]: [1.0, 1.584962500721156, 2.0]
Here we see that the total correlation is equal to \(\log_2{m}\) regardless of \(n\).
The total correlation follows a nice decomposition rule. Given two sets of (not necessarily independent) random variables, \(A\) and \(B\), the total correaltion of \(A \cup B\) is:
In [7]: from dit.multivariate import coinformation as I
In [8]: d = n_mod_m(4, 3)
In [9]: T(d) == T(d, [[0], [1]]) + T(d, [[2], [3]]) + I(d, [[0, 1], [2, 3]])
Out[9]: True
Visualization
The total correlation consists of all information that is shared among the variables, and weights each piece according to how many variables it is shared among.
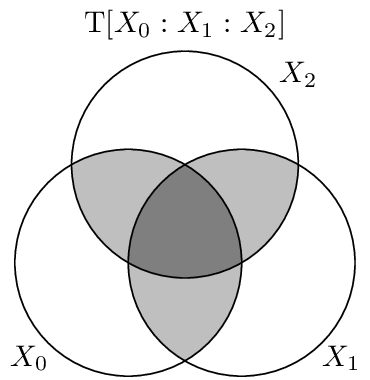
API
- total_correlation(dist, rvs=None, crvs=None)[source]
Computes the total correlation, also known as either the multi-information or the integration.
- Parameters:
dist (Distribution) – The distribution from which the total correlation is calculated.
rvs (list, None) – A list of lists. Each inner list specifies the indexes of the random variables used to calculate the total correlation. If None, then the total correlation is calculated over all random variables, which is equivalent to passing rvs=dist.rvs.
crvs (list, None) – A single list of indexes specifying the random variables to condition on. If None, then no variables are conditioned on.
- Returns:
T – The total correlation.
- Return type:
Examples
>>> d = dit.example_dists.Xor() >>> dit.multivariate.total_correlation(d) 1.0 >>> dit.multivariate.total_correlation(d, rvs=[[0], [1]]) 0.0
- Raises:
ditException – Raised if dist is not a joint distribution or if rvs or crvs contain non-existant random variables.